
Many people have heard about DevOps as this technique breaks records in IT areas. The Dev particle comes from the word Development, and Ops means Operations. That is, the relationship between Development and Operations is obtained. This methodology burst into the world in 2009 and became a reconciliation for programmers and system administrators (by the way, it worked!).
Since then, many have wanted to become a DevOps engineer due to this conciliatory specialty’s popularity and good pay. In this article, we will talk about DevOps metrics. Of course, everything is based on the maximum lightning speed of the code and uninterrupted delivery.
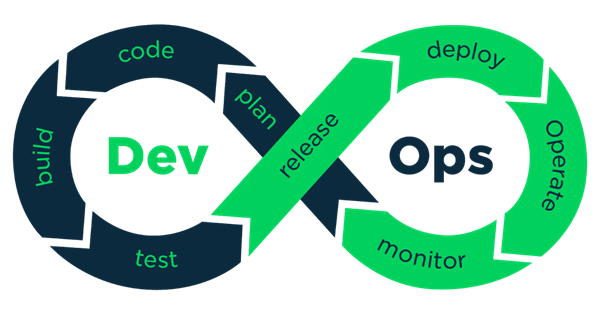
This lays the foundation for the eight metrics!
- Time taken to deploy. Monitoring this moment can answer many questions; you can easily identify any problems.
- Time it takes to execute. Remember the basis of all metrics. Speed! The length of time between launch and deployment also plays a key role. You know how much time was spent on this in general, and this will serve as a reference when we start a new workflow.
- Feedback from customers. To improve your work, don’t be afraid of feedback. Always consider what customers say. This metric helps understand what to change in the application. Thanks to customers, you will understand what needs to be removed, added, or changed. If they write to technical support or openly write a dissatisfied comment, this is precisely what will strengthen the workflow! And if you also declare that the problem has been eradicated, this will increase your status in users’ eyes, and they will mark you as caring.
- Automated tests. Remember that DevOps is very dependent on automation! To overclock the speed, you need to conduct unit and functional testing.
Let’s pause for a second. Answer the question: what will unconditionally help in speeding up and optimizing? Devops Consulting Services is the answer to this question!
If you are concerned about: Variations in the configurations of the development, testing, and production environments, DevOps Consulting may be the solution.
So, let’s continue.
- The time it takes to recover from failures. Everything happens by trial and error. Failures happen, and this is normal; this is natural! However, it is also worth taking advantage of this. Calculate how long it takes to recover, and if such a situation happens again, it will be much easier to work with her.
- Time taken to discover a problem. We figured out how much time it takes to destroy. But don’t forget, detecting the problem takes some time too! Arm yourself with thorough monitoring, and then you will quickly see failures.
- Error rate. Monitoring this aspect will also greatly help you in understanding the application. If problems appear frequently, and suddenly there is still a specific pattern, something is wrong with the performance. Don’t ignore it.
- Oh no, failed deployments. This is a terrible dream of a programmer that haunts gloomy nights. But if this suddenly becomes a reality, do not panic. Keep an eye on this metric; you might even plan for failed deployments because speed is at stake!
Lastly, don’t forget that you need a solid foundation. Check this site –https://itoutposts.com/infrastructure-management-services/, it will help you with this!


